Saadman Ahmed, Md Shoaib Shahriar Ibrahim and Munawar Hafiz of OpenRefactory write about how the DeepSeek R1 model compares with other LLM models when they are used in driving an AI agent. Edited by Charlie Bedard
-
- DeepSeek has been released as Open Source under an MIT license although the training data information is not available.
- DeepSeek R1 offers similar performance to the OpenAI o1 model at a fraction of the cost (30X less expensive).
- When compared with the OpenAI benchmark, DeepSeek performed close to the OpenAI o1 model for natural language processing tasks and performed a little better than the OpenAI o1 model for math and code generation tasks.
People have already started test driving these technologies. These tests make qualitative evaluations by comparing the outcomes generated by DeepSeek with those generated by OpenAI. There is one such demonstration on YouTube that shows that DeepSeek generated code may have some compilation errors, but fixing those errors is not that hard. Even after the errors are fixed, the solution provided by OpenAI for an open ended coding model is more elegant than that provided by DeepSeek.
Kyle Orland provides a detailed comparison of outputs from different domains (creative, mathematics, code generation). The observation, as expected from a qualitative study, was that there was no clear winner. Quoting from that post, “DeepSeek’s R1 model definitely distinguished itself by citing reliable sources to identify the billionth prime number and with some quality creative writing in the dad jokes and Abraham Lincoln’s basketball prompts. However, the model failed on the hidden code and complex number set prompts, making basic errors in counting and/or arithmetic that one or both of the OpenAI models avoided.”
In this article we will describe an experiment to put both the reasoning and the generation capability to test. We will not be testing the code generation capabilities; others have done that. Instead, we will compare how the flagship LLM models from the leading AI companies performed in an agentic AI architecture to complete a specific task.
Use Case for the Agent and the Architecture
We have developed an agent that, given the GitHub URL of an open source package, attempts to build the package automatically and run the unit tests.
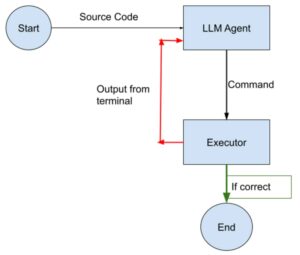
-
- an LLM agent, which generates commands, and
- an executor agent, which executes those commands and returns output to the LLM agent, thus creating a feedback loop.
The process starts with the creation of an Ubuntu 22.04 base Docker image. The LLM agent is provided with the README file and prompted to generate a command for building the package and executing unit tests automatically. The LLM agent is instructed to output “DONE” upon successful completion of the build. The command from the LLM agent is then extracted and sent to the executor agent Docker container. The terminal output is relayed back to the LLM agent, which is then asked to provide the next command. If the build is successful, the LLM agent outputs “DONE” instead of a command. The executor agent terminates its container upon receiving “DONE”.
In this study, we evaluate the performance of several LLM-driven build automation agents operating within a controlled execution environment.
Test Setup
We randomly selected 15 projects from the Jenkins dependency tree for evaluation. Jenkins has 172 dependencies. We picked 15 without considering any criteria such as project size, project popularity, etc. This was to avoid any prior bias about some projects being hard to build compared to the others. Because these are dependencies of Jenkins, all are Java projects and therefore they use common Java build tools (e.g., Maven, Gradle, etc.,). In future, we plan to extend the experiment with projects written in other languages.
For the experiment, a total of six models were employed to drive the agents and attempt to build the projects and run tests.
-
- DeepSeek R1,
- ChatGPT O1-Preview,
- Gemini-2.0-Flash,
- Claude 3.5 Sonet,
- ChatGPT-4o-Latest, and
- Gemini-2.0-Flash-Exp,
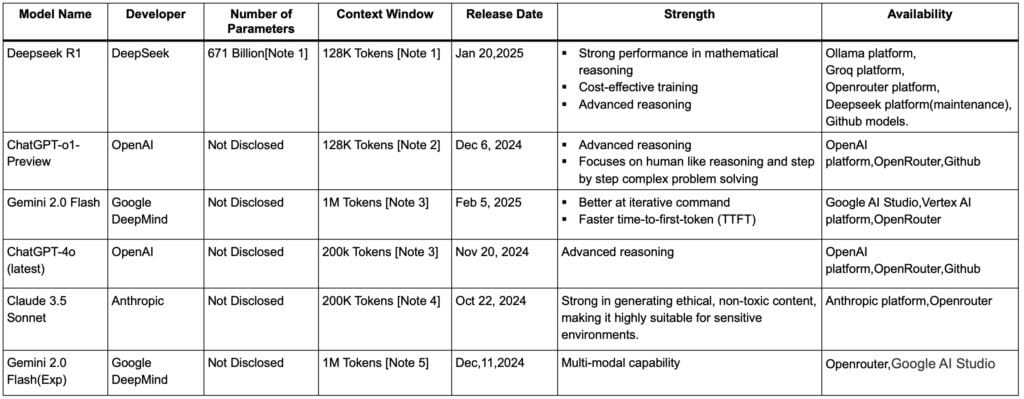
The flagship models from four organizations, DeepSeek, OpenAI, Google and Anthropic are used in the experiment. Two extra models were used, one from OpenAI and one from Google. The ChatGPT-4o model from OpenAI performed exceptionally in coding related tasks. It achieved an 87.2% score on the HumanEval coding test, surpassing models like Claude 3 Sonnet 73% and Claude Haiku (75.9%). Google’s Gemini 2.0 Flash has only been available for a few days. When we started running the experiment, we used the Gemini 2.0 Flash Exp model. We share results using both versions of the Gemini model.
The Deepseek R1 model is also new. This created some problems in the experimentation because the official API for this model was unavailable due to maintenance. Ollama provides a free version of DeepSeek R1 models with different parameter configurations. But it does not allow API integration. Groq offers a distilled and faster version of the model but it is limited in token size. GitHub also provides free access to the DeepSeek R1 model (including the 671 Billion parameter version), but its usage is capped to 6,000 tokens.
We accessed the paid version of the DeepSeek R1 model from OpenRouter.ai. The Nitro version was selected for unrestricted token access and enhanced performance.
The results obtained from these models were comprehensively cross-compared to evaluate their efficiency, effectiveness, and suitability for command generation tasks within the project’s scope.
Results
DeepSeek R1 performs better than the rest.
Table 1 shows the comparative results of the LLMS that were used.
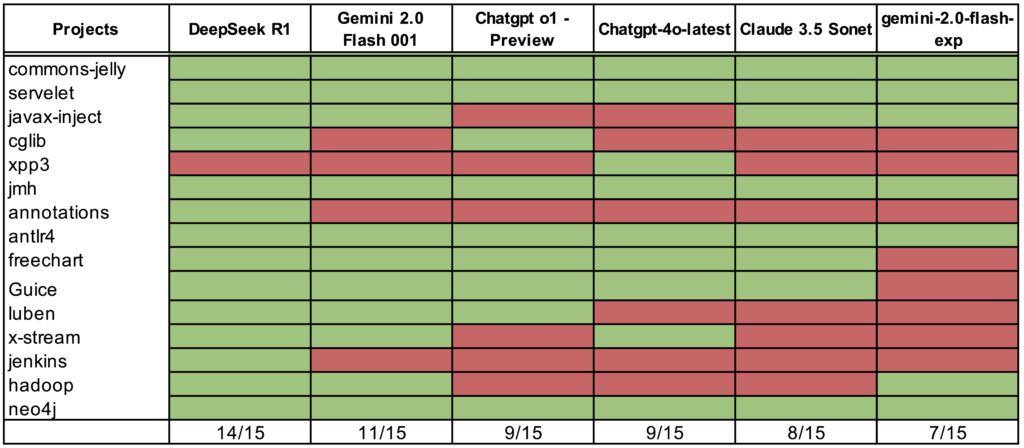
DeepSeek performs significantly better than the other flagship LLM models. It drives the agent to build 14 of the 15 projects. The next best was Gemini 2.0 Flash 001 which was able to build 11 of the 15 projects. OpenAI ChatGPT was able to build 9 out of 15 projects.
When we designed the experiment, we expected about 60% success rate. The result generated by the OpenAI o1 model was on par with that expectation. But DeepSeek exceeded expectations by being able to build 93% of the projects.
The advantages come from some design choices
DeepSeek R1 distinguishes itself architecturally by using a Mixture‑of‑Experts (MoE) design that activates only a small, specialized subset of its overall parameters for each query—about 37B out of 671B—thereby reducing computational overhead while preserving high performance. This specialization enhances efficiency and performance across various domains.
Moreover, it leverages a multi-stage RL framework (including Group Relative Policy Optimization or GRPO which is considered as the math behind this powerful model) which enhances reasoning capabilities by refining reward signals and optimizing decision-making paths. This approach allows the model to develop longer, more accurate reasoning chains than other LLM’s. This approach reduces reliance on extensive human data labeling, making the training process more efficient. DeepSeek R1 achieves high performance with fewer computational resources compared to some industry leaders.
In contrast, Gemini 2.0 Flash relies on a multimodal transformer architecture that integrates various data types (text, images, audio, and video) and supports extremely long context windows, while OpenAI’s 4o/o1 models use standard dense transformer architectures optimized respectively for safe, everyday conversation (4o) or advanced reasoning via additional reinforcement learning (o1). Claude Sonnet incorporates constitutional AI methods to ensure output safety at the expense of some reasoning depth.
DeepSeek R1’s superior performance in reasoning tasks—especially in mathematics and coding—stems from its multi‑stage reinforcement learning framework based on Group Relative Policy Optimization (GRPO), which refines reward signals and enhances its chain‑of‑thought processes. This combination of selective expert activation and efficient, RL‑driven training enables DeepSeek R1 to achieve comparable or better reasoning capabilities.
Other models often sacrifice deep, specialized reasoning for broader functionality. For example, Gemini 2.0 Flash focuses on multimodal integration and extended context handling, which can dilute its capacity for intricate chain‑of‑thought reasoning. OpenAI’s GPT‑4o and its o1 variant require extensive computational resources and use opaque RL tuning processes that reduce cost efficiency and transparency compared to DeepSeek R1’s lean MoE approach. Similarly, Claude Sonnet emphasizes safety and controlled outputs via heavy RLHF and constitutional AI, which can limit its creative and flexible reasoning on complex tasks.
Three Case Studies
Let us discuss three specific cases.
Case 1: OpenAI driven agent makes a mistake and fails to Recover
In the case of the cglib project, only DeepSeek was able to build the package. Here, the first requirement was to install Java and Maven. In both cases, the LLM agents tried to ensure that these dependencies were correctly installed before proceeding with the build. The DeepSeek R1 agent correctly installed the required Java 8 Development Kit (JDK) and Maven tools, as specified by the project’s documentation.
The OpenAi gpt-4o agent, however, mistakenly installed OpenJDK 17 instead, which led to compatibility issues during the build process. When the agent proceeded to build, it got the error messages.
[ERROR] Source option 6 is no longer supported. Use 7 or later.
[ERROR] Target option 6 is no longer supported. Use 7 or later.
Here is where things got interesting. In response, the agent attempted to resolve this issue by using a sed command to modify the pom.xml file, changing the source and target java version from 6 to 7:
Sed -I ‘s/6<\/source>/7<\/source>/g;s/6<\/target>/7<\/target>/g’ pom.xml
Though this modification addressed the specific error in the build configuration, it did not resolve the deeper incompatibility issue between the project’s codebase and the newer JDK version.
The build failed again with the same error, revealing that the error was not just with the source and target version but also with the overall compatibility of the project with JDK 17. Despite the repeated failures, the agent continued to run the same mvn clean install command without adapting its approach.
Thus, the repeated use of the same ineffective fix without deeper analysis or adjustments underscores the model’s limitation to consider alternative solutions, such as downgrading to the required OpenJDK 8, which was essential for compatibility with the project’s dependencies and build configuration.
Case 2: DeepSeek showing intelligence by recovering from multiple errors
For building the jsinterop-annotations project, DeepSeek R1 acted as an intelligent agent, dynamically generating and executing shell commands based on system feedback. The process began with an attempt to install Bazelisk, a tool required for Bazel-based builds, using npm:
npm install -g @bazel/bazelisk
However, this command failed due to the absence of npm. The agent correctly identified the missing dependency and installed Node.js and npm to enable package management:
sudo apt-get update && sudo apt-get install -y nodejs npm
Once npm became available, the agent successfully installed Bazelisk and created an alias to ensure consistency when invoking Bazel commands:
alias bazel=bazelisk
bazel –version
Following the setup of Bazel, DeepSeek R1 initiated the project’s release script, release_jsinterop_annotations.sh, which was responsible for compiling the code and generating the required artifacts:
chmod +x maven/release_jsinterop_annotations.sh
./maven/release_jsinterop_annotations.sh –version local –no-deploy
However, during execution, an error occurred indicating that the jar command was missing, suggesting that the Java Development Kit (JDK) was not installed. The agent correctly figured out this issue and installed OpenJDK 11, a version compatible with the project’s requirements:
chmod +x sudo apt-get install -y openjdk-11-jdk which jar
After verifying the presence of the jar command, the AI resumed the build process by re-running the release script. At this stage, the build encountered a Git-related configuration issue, requiring user identity setup. DeepSeek R1 adapted by setting the global Git user identity, a necessary step for Git-based versioning and commit operations.
In a nutshell, the agent exhibited context-aware decision-making, dynamically modifying its approach based on real-time execution. The adaptability is shown through the following key tasks:
-
- Resolved dependency issues step-by-step rather than making assumptions.
- Identified and installed required tools (npm, Bazelisk, OpenJDK).
- Executed verification commands (e.g., which jar, bazel –version).
- Addressed build-breaking issues dynamically, such as the missing Git configuration.
Case 3: Deepseek R1 failed to build xlib while OpenAi succeeded
The OpenAi-gpt-4o-latest agent successfully guided the system through building the xpp3 project by ensuring all necessary dependencies, including OpenJDK 17 and Maven, were installed. It provided commands to verify the installations and instructed the system to navigate to the project directory and execute mvn clean install to compile and package the application.
Interestingly, Deepseek R1 agent failed to build this. DeepSeek attempted to build the project but encountered issues due to missing Java 8 dependencies. It tried updating the build configuration and installing OpenJDK 8, but the process got stuck in an interactive prompt (update-alternatives –config java), which required manual input to select the correct Java version.
The key difference between OpenAI’s GPT-4o and DeepSeek R1 was in their approach to dependency management. GPT-4o installed OpenJDK 17 and Maven explicitly, verified their installation, and guided the system step by step. It ensured all prerequisites were met before starting the build. In contrast, DeepSeek R1 lacked automation to handle interactive inputs and failed to configure Java properly. This led to a stalled process, making its approach less effective.
Key Takeaways
- DeepSeek R1 performs better than the flagship AI models from three other companies in our tests.
- DeepSeek R1’s exceptional performance in our agentic architecture underscores the power of its unique design and training. Its Mixture-of-Experts (MoE) architecture combined with its multi-stage reinforcement learning framework incorporating Group Relative Policy Optimization (GRPO) contributes to the superior capability.
- In our specific use case – automatically building and testing open-source projects – DeepSeek R1’s strengths were particularly advantageous. Our agent, which we developed, required the LLM to not only understand project documentation (READMEs) but also generate and execute a sequence of shell commands within a Docker environment. This demanded both natural language understanding and a kind of “practical reasoning” about how software builds work. DeepSeek’s ability to create accurate chains of thought, to understand dependencies, and to dynamically adapt to the output of the executor agent (the build process itself) was crucial.
- In future, we plan to expand the test into building programs in other languages.
Credits
Saadman Ahmed and Md Shoaib Shahriar Ibrahim, AI/ML engineers of OpenRefactory, performed the experiments. They were joined by Munawar Hafiz, Founder of OpenRefactory, to write the story.





